
Apache Kafka for HDInsight – Data Sources and Ingestion
For customers who have an existing solution based on Apache Kafka for HDInsight and want to move it to Azure, this is the product of choice. From a Microsoft perspective, the same solution can be achieved using Event Hubs and IoT Hub with Azure Stream Analytics. Each of these product pairings can ingest streaming data from streaming sources on an unprecedented volume, velocity, and varied scale. Chapter 1 introduced Apache Kafka, and Chapter 2 provided more in‐depth detail, which should be enough to respond to any questions you might get on the exam. The primary focus for the exam is on the Microsoft streaming products; however, you might see a reference to Apache Kafka for HDInsight. When you provision an HDInsight cluster on Azure, you must select the cluster type (see Figure 3.85). Refer to Chapter 1 for more about cluster types.
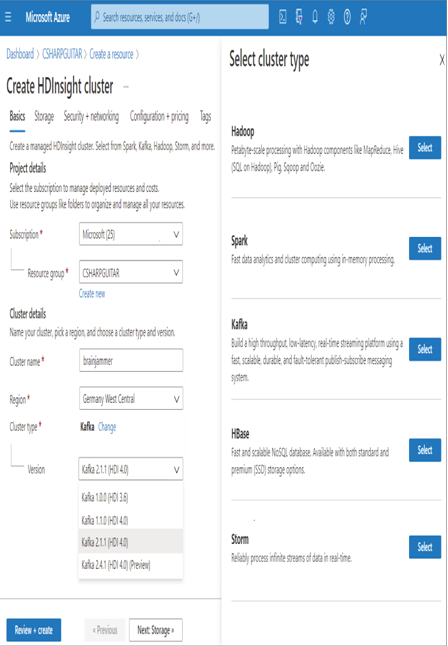
FIGUER 3.85 Choosing an Apache Kafka for HDInsight cluster type
The required nodes to run Apache Kafka for HDInsight consist of head, Zookeeper, and worker nodes. As shown in Figure 3.86, there is a requirement for storage per worker node.
The head node is the node you can Secure Shell (SSH) into to manually execute applications and that will run across the HDInsight cluster. Processes that manage the execution and management of the HDInsight cluster run on the head node as well. The Zookeeper node is software that monitors and keeps track of the names, configuration, synchronization, topics, partitions, consumer group, and much more relating to Kafka. The Zookeeper node is a required component to run Kafka on HDInsight, and the head node is required for all HDInsight cluster types. Worker nodes provide the compute resource, CPU, and memory to perform the custom code and data processing required by the application. You might have noticed some similar terminology between Apache Kafka and Event Hubs, as shown in Table 3.22.
TABLE 3.22 Apache Kafka vs. Event Hubs terminology
| Kafka | Event Hubs |
| Cluster | Namespace |
| Topic | Event Hub |
| Partition | Partition |
| Consumer group | Consumer group |
| Offset | Offset |
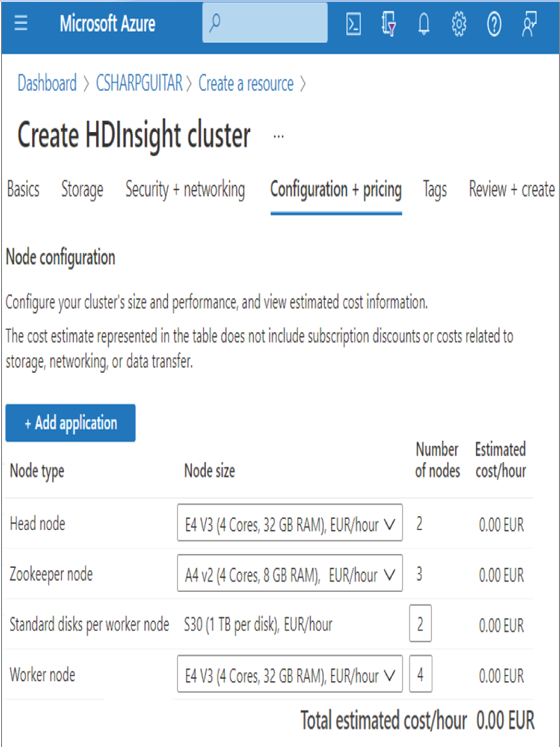
FIGUER 3.86 Apache Kafka for HDInsight Kafka nodes
The only term in Table 3.22 that has not been explained yet is offset. The offset is a way to uniquely identify an event message within a partition. If you need to stop and restart the processing of events for a given partition, you can use the offset to determine where you need to start from.