
Create an Azure Event Namespace and Hub – Data Sources and Ingestion
- Log in to the Azure portal at https://portal.azure.com ➢ enter Event Hubs in the search box ➢ click Event Hubs ➢ click the + Create link ➢ select a subscription ➢ select a resource group ➢ provide a namespace name (I used brainjammer) ➢ select a location ➢ select the Basic Pricing tier (since this is not production) ➢ leave the default value of 1 for Throughput Units ➢ click the Review + Create button ➢ and then click Create.
- Once provisioned, navigate to the Event Hub Namespace Overview blade ➢ select the + Event Hubs link ➢ name the event hub (I used brainwaves) ➢ leave the default of 2 for Partition Count ➢ and then click Create.
- Choose the Shared Access Policies navigation menu item, and then click RootManageSharedAccessKey. Note the primary keys, secondary keys, and connection string.
It is possible to create an additional policy with fewer rights. The RootManageSharedAccessKey policy has full access. You might consider creating a policy with the minimum access necessary, perhaps Send Only. It depends on your requirements, but it is good practice to provide the minimum amount of access required to achieve the work, in all cases. This event hub will be used for numerous other examples in the coming chapters. To extrapolate a bit on Figure 1.22 and to expand a bit into the Event Hubs internals, take a look at Figure 3.77.
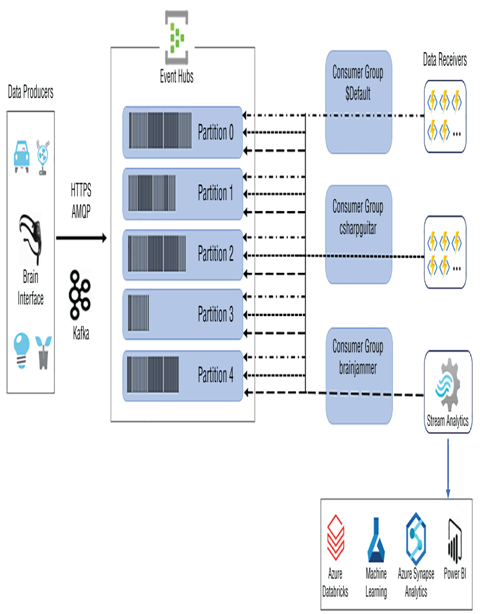
FIGUER 3.77 Event Hubs data ingestion
When you implement the Event Hubs namespace and hub in a later chapter, Chapter 7, “Design and Implement a Data Stream Processing Solution,” you will be exposed to some of the concepts shown in Figure 3.77. The first item you might notice in the figure is Kafka. Note that it is possible to redirect data producers to send data to an event hub instead of being required to manage an Apache Kafka cluster. This can happen without any code changes on the Kafka‐focused devices. When you provision an event hub, you select the number of partitions it will have. Partitions enable great parallelism, which translates into the capability to handle great levels of velocity and volumes of incoming data. The incoming data is load balanced across the partitions. Each subscriber to a consumer group will have access to the data at least once. That means the incoming data stream can be consumed by more than a single program or client. One such program is Azure Stream Analytics, which can perform real‐time analytics on the incoming data. The conclusion made by Azure Stream Analytics can then be forwarded or stored in numerous other Azure products. Learn from the data using Azure Machine Learning and store the data in Azure Synapse Analytics or Azure Databricks, for further transformation, or Power BI, for real‐time visualizations.
Azure Stream Analytics
To begin this section, complete Exercise 3.17, which walks you through the provisioning of an Azure Stream Analytics job.