
Implement Different Table Geometries with Azure Synapse Analytics Pools – The Storage of Data
To effectively use the massively parallel processing (MPP) architecture with a SQL pool, you need to understand table geometries. Table geometries specify how data is sharded into distributions on your existing compute nodes. These table geometries optimize the performance of the queries that run on them and are defined as you create the table. There are three types, which you already know about.
- Round‐robin is optimal for staging/temporary tables (default).
- Hash is optimal for fact and large dimensional tables.
- Replicated is optimal for small dimensional tables in a star schema.
To implement a round‐robin distributed table, execute the following SQL statement. The result is an even distribution of rows from the table across randomly selected compute nodes.
CREATE TABLE [staging].[PlayingGuitar]
([SESSION_DATETIME] DATETIME NOT NULL,[READING_DATETIME] DATETIME NOT NULL,[SCENARIO] NVARCHAR (100) NOT NULL,[ELECTRODE] NVARCHAR (50) NOT NULL,[FREQUENCY]NVARCHAR (50) NOT NULL, [VALUE] DECIMAL(7,3) NOT NULL)WITH(CLUSTERED COLUMNSTORE INDEX,DISTRIBUTION = ROUND_ROBIN)
In Exercise 3.7 you created a hash‐distributed table, which resembled the following SQL statement. This results in all the data from the table being distributed to different nodes per the column identified in the hash. In this case the value is the FREQUENCY, but it could also be ELECTRODE or SCENARIO. Because this table contains all the readings from all scenarios and sessions, it is the largest one; therefore, it is a good candidate for this distribution type, so it is broken down into smaller, queryable datasets. Tables that require JOIN or aggregation command statements can also realize performance gains using the hash distribution model.
CREATE TABLE [brainwaves].[FactREADING]
([SESSION_DATETIME] DATETIME NOT NULL,[READING_DATETIME] DATETIME NOT NULL,
[SCENARIO] NVARCHAR (100) NOT NULL,[ELECTRODE] NVARCHAR (50) NOT NULL,
[FREQUENCY]NVARCHAR (50) NOT NULL,[VALUE] DECIMAL(7,3) NOT NULL) WITH(CLUSTERED COLUMNSTORE INDEX,DISTRIBUTION = HASH ([FREQUENCY])
A replicated distribution places a copy of the table data on each node in the cluster. This provides optimal performance for small tables.
CREATE TABLE [brainwaves].[DimFREQUENCY]
([FREQUENCY_ID] INT NOT NULL,[FREQUENCY] NVARCHAR (50) NOT NULL,[ACTIVITY] NVARCHAR (100) NOT NULL)
WITH(CLUSTERED COLUMNSTORE INDEX,DISTRIBUTION = REPLICATE)
There is a file named tableGeometries.txt in the Chapter04 directory on GitHub at https://github.com/benperk/ADE. Consider performing the steps in Exercise 4.2 but instead using the table geometries distribution SQL script. Note the new schemas and be sure to create them as well.
Implement Data Redundancy
When something is redundant, it means that the item is not needed. In many scenarios the redundant object is never needed again. In other circumstances, however, it might not be needed at the moment but may be in the future. Having a copy of a database, for example, may be redundant, but if the primary database is harmed, having this redundancy will be very helpful. Data redundancy can be important in cases where a user executes an unintended update, truncate, or delete that impacts a massive amount of data. Another possibility is for resiliency in case of a problem at the datacenter where your data exists.
Human Error
Unintentional actions happen, such as deleting files, dropping a table, or truncating data. Hopefully none of those happen very often, but if they do, there are actions you can take to recover. Point‐in‐time restore (PITR) can be helpful in scenarios where data has been deleted or modified in a way that is not easily recoverable. PITR is dependent on something called a snapshot, which is an action that creates a restore point. So, what needs to happen is that when a human error causes data loss or corruption, you can restore the data by using a snapshot taken before the corruption. From an Azure Synapse Analytics dedicated SQL pool perspective, snapshots are a built‐in feature. PITR follows an eight‐hour recovery point objective (RPO), which means when your data gets into an unwanted state, the maximum time to get recovered should be 8 hours. RPO defines how much data can be lost at maximum, meaning that you can lose up to 8 hours of data. To view the most recent dedicated SQL pool snapshot in Azure Synapse Analytics, execute the following query in a SQL script:
SELECT TOP 1 *
FROM sys.pdw_loader_backup_runs
ORDER BY run_id DESC
Notice the results, as shown in Figure 4.7, and what can be concluded from them.
You can infer from the query results information like when the snapshot took place, when it was completed, how long it took, the type, the mode, the status, and the progress.
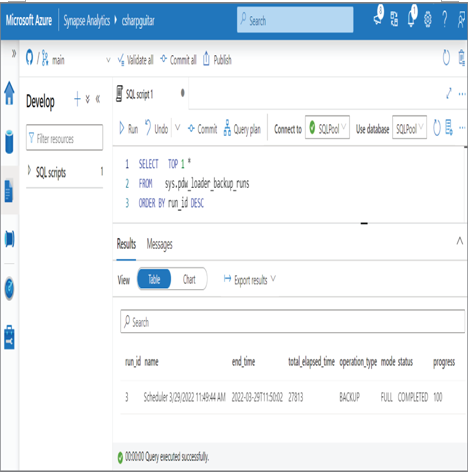
FIGURE 4.7 Data redundancy snapshots