
Implement Partitioning – The Storage of Data-1
There are two primary reasons to implement partitioning: manageability and performance. From a manageability perspective, your tables are organized into a structure that makes their content discoverable. That makes it possible to deduce the content of the data on a table by its name, for example. If the variety of data in a table is too great, then it is harder to determine how to use the data and what purpose it has. Splitting the data from one large table in a logical manner into a smaller subset of tables can help you understand and manage the data more efficiently. Figure 4.2 illustrates how you might partition a large table into smaller ones. This is often referred to as vertical partitioning.
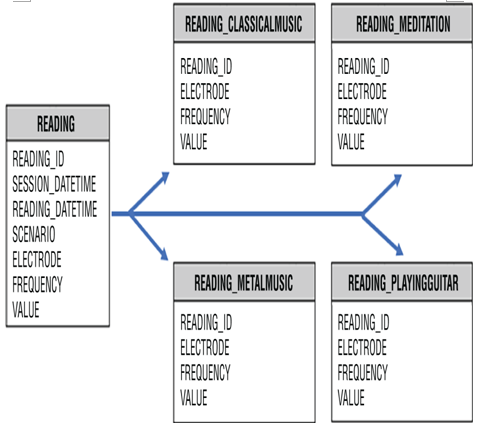
FIGURE 4.2 Azure Synapse Analytics SQL partitioning
The other reason to implement partitioning is for performance. Consider that the READING table in Figure 4.2 contains millions of rows for all brainjammer scenarios. If you want to retrieve data for only a single scenario, then the execution could take some time. To improve performance in that scenario, you can create tables based on the scenario in which the reading took place.
Foreign keys are not supported in dedicated SQL pools on Azure Synapse Analytics. Both a primary key and a unique constraint are supported but only when the NOT ENFORCED clause is used. A primary key also requires the NONCLUSTERED clause.
You can implement partitioning using a Spark pool by running the following commands, which you learned a bit about in Chapter 3:
%%pyspark
df = spark.read \.load(‘abfss://[email protected]/SessionCSV/*_FREQUENCY_VALUE.csv’, \format=’csv’, header=True)
df.write \.partitionBy(‘SCENARIO’).mode(‘overwrite’) \.csv(‘/SessionCSV/ScenarioPartitions’)
The partition is created on the same ADLS the loaded data file is retrieved from and loaded into a DataFrame. The result of the partitioning resembles Figure 4.3.
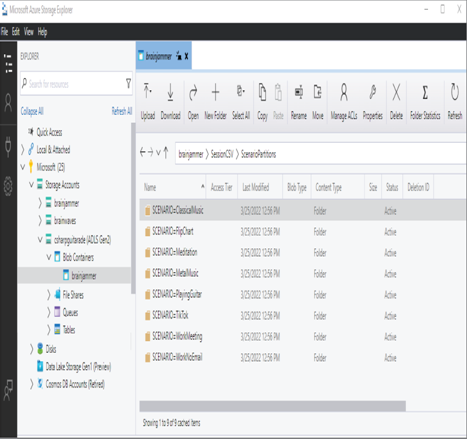
FIGURE 4.3 Azure Synapse Analytics Spark partitioning from Storage explorer
When you query the specific partition using the following code snippet, the result contains only readings from the Meditation scenario. This is in contrast to loading and querying the CSV file for the readings.
data = spark.read.csv(‘/SessionCSV/ScenarioPartitions/SCENARIO=Meditation’)
data.show(5)
To gain some hands‐on experience for these concepts, complete Exercise 4.2.