
Implement Partitioning – The Storage of Data-2
- Log in to the Azure portal at https://portal.azure.com ➢ navigate to the Azure Synapse Analytics workspace you created in Exercise 3.3 ➢ on the Overview blade, click the Open link in the Open Synapse Studio tile ➢ select the Data hub ➢ expand the SQL database menu ➢ expand the dedicated SQL pool you created for Exercise 3.7 ➢ hover over the Schemas folder ➢ click the ellipse (…) ➢ click New SQL Script ➢ click New schema ➢ execute the CREATE SCHEMA SQL command after providing a name (I used reading).
- Execute the SQL syntax located in the Chapter04/Ch04Ex02 directory on GitHub at https://github.com/benperk/ADE. In the partitionSQL.txt file, view the newly created tables by refreshing the Tables folder.
- Select the Linked tab within the Data hub ➢ expand Azure Data Lake Storage Gen2 ➢ navigate to the ALL_SCENARIO_ELECTRODE_FREQUENCY_VALUE.csv file, which you uploaded earlier, or download it from the Chapter03/Ch03Ex09 folder on GitHub ➢ navigate to the file via the Linked service ➢ choose the New Notebook drop‐down menu ➢ click Load to DataFrame ➢ attach the Spark pool you created in Exercise 3.4 from the Attach To drop‐down ➢ and then enter the following code snippet (adjust the paths accordingly):
%%pyspark
df = spark.read \
.load(‘abfss://[email protected]/SessionCSV/…ODE_FREQUENCY_VALUE.csv’, \
format=’csv’, header=True)
df.write \
.partitionBy(‘SCENARIO’).mode(‘overwrite’).csv(‘/SessionCSV/ScenarioPartitions’)
data = spark.read.csv(‘/SessionCSV/ScenarioPartitions/SCENARIO=PlayingGuitar’)
data.show(5)
The code snippet is available in the Chapter04/Ch04Ex02 directory on GitHub, in a file named partitionSpark.txt. The output resembles Figure 4.4.
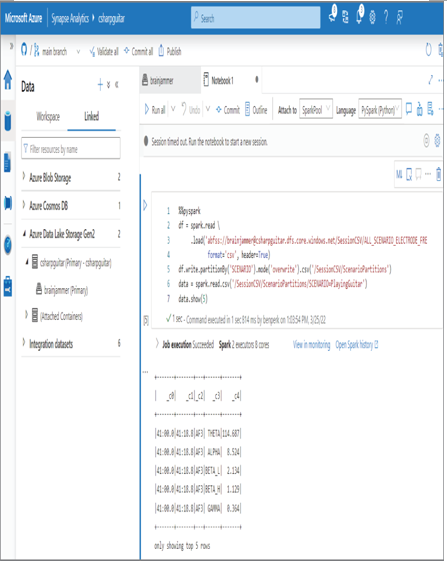
FIGURE 4.4 Azure Synapse Analytics Spark partitioning
Implement Sharding
Sharding is a form of data partitioning, sometimes referred to as horizontal partitioning. Both sharding and partitioning are concerned with reducing the size of a dataset. The primary difference is that sharding implies that the data partitions will be spread across multiple nodes (i.e., computers). Vertical partitioning can also be spread across multiple nodes, though more commonly just across tables or databases. A partition concerns the grouping of data that will run within a single database instance. There is a lot of overlapping terminology relative to these two concepts, including the terms vertical and horizontal. In some scenarios vertical and horizontal partitioning can be applied to both partitioning and sharding. For now, you can learn the basics here and then, as you progress, you can dig deeper into the complexities that drive your choice in your given context. Consider the READING table shown in Figure 4.5.
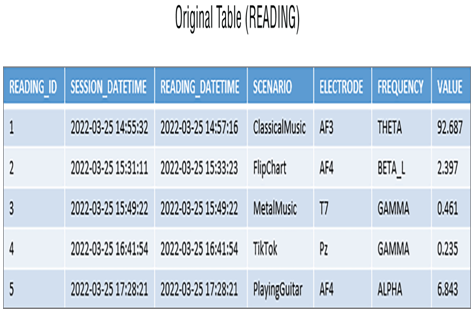
FIGURE 4.5 Sharding original table
To shard the READING table into smaller sets of data in separate tables, you can group the data alphabetically, as shown in Figure 4.6.
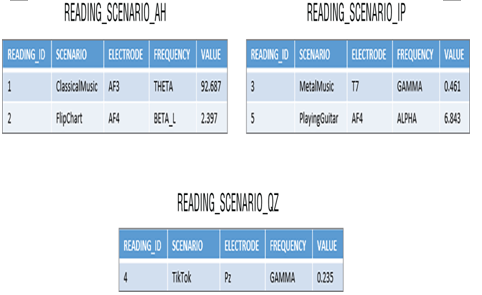
FIGURE 4.6 Sharding sharded table
Notice that the separation of data is based on the beginning character of the brainjammer scenario. The way you shard data requires some analysis of the original table. Notice that the tables are appended with characters _AH, _IP, and _QZ. This indicates that scenarios beginning with the letters A through H are placed into the READING_SCENARIO_AH table; scenarios beginning with I through P are placed into their own table; and so on. The point is, you need to balance the data so that you have a similar number of rows per sharded table. A table containing A–H might not be the best solution in a different situation, so you need to analyze the data in the original table to determine the best way to shard your data. You should perform analysis periodically to make sure the tables remain comparable in size. If you receive a lot of a scenarios that start with the letters I through P, you may need to reshuffle and reevaluate the shards.
When you need to retrieve data for a specific scenario, you will know that the data is sharded by scenario name. Your queries can therefore target the appropriate tables based on that knowledge. There is a file named shardingSQL.txt in the Chapter04 directory on GitHub at https://github.com/benperk/ADE. Consider performing the steps in Exercise 4.2 but using the sharding SQL script instead. Note that the READING table will already exist from previous exercises; just remove that part of the SQL statement, if it causes problems.