
Table – Data Sources and Ingestion
When you navigate to the Create New Table page, you will see three tabs: Upload File, DBFS, and Other Data Sources. The Upload File feature supports users uploading files directly onto the platform, which is a very common scenario when using Azure Databricks. This feature supports that through dragging and dropping a file onto the page or browsing for it using a file picker window. The file must be in a supported format, and you will need to select a running cluster to perform the creation and preview. If you want to place the file into a folder other than the /FileStore/tables/ folder, then you have the option to define that in the DBFS Target Directory text box. When a table is created in this manner, it is placed into a database named default.
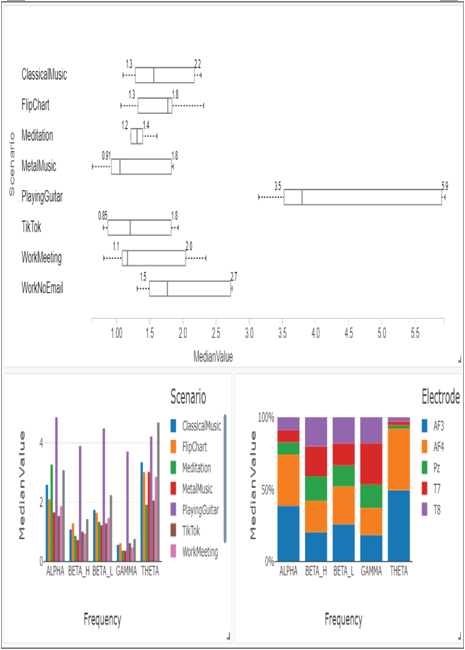
FIGUER 3.71 Azure Databricks brain wave charting example
The DBFS tab provides a navigation feature that allows you to traverse the contents found within the /FileStore/* and other folders. This is similar to Windows File Explorer, for example, but the feature is in the browser. Clicking files in the folder gives you a direct path for creating tables for them to be queried from. The remaining tab, Other Data Sources, provides a list of connectors that Azure Databricks can retrieve data from. Examples of connectors include Azure Blob Storage, ADLS, Kafka, JDBC, Cassandra, and Redis. Selecting a connector and clicking Create Table in Notebook will result in a template that walks you through the connection being rendered. Follow the instructions and then perform your ingestion, transformation, and/or analytics.
Cluster
The Create Cluster page was illustrated in Figure 3.65. All the attributes and configurations found on this page have been called out already after Exercise 3.14.
Job
A job is similar to an activity that is part of a pipeline. There are numerous types of jobs, which are selectable from the drop‐down text box shown in Figure 3.72.
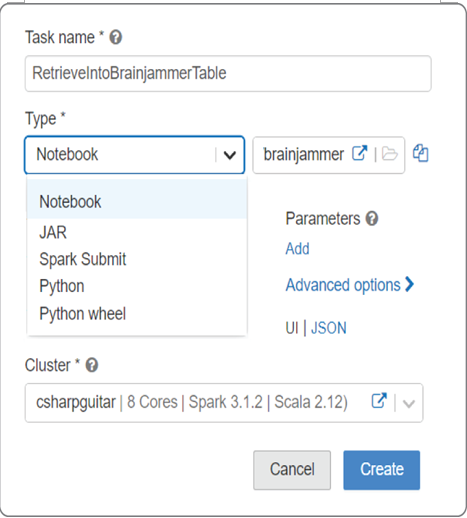
FIGUER 3.72 Azure Databricks workspace jobs
Table 3.17 describes the possible types of jobs.
TABLE 3.17 Azure Databricks job types
| Type | Description |
| Notebook | Runs a sequence of instructions that can be executed on a data source |
| JAR | Executes and passes data parameters to JAR components |
| Spark Submit | Runs a script in the Spark /bin directory |
| Python | Runs the code within a targeted Python file |
| Delta Live Tables | Executes Delta pipeline activities |
| Python Wheel | Executes a function within a .whl package |
After configuring the job, you can run it immediately or use the built‐in platform scheduling capabilities to run it later.