
Workspace – Data Sources and Ingestion
The Workspace section provides access to the assets that exist within the workspace. For example, you created an Azure Databricks workspace in Exercise 3.14. Depending on your permissions, you can find shared workspaces or workspaces allocated directly to you or other users.
Repos
Repository‐level Git is part of the Azure Databricks product. This means you can create a local source code repository within the workspace, called a Repo, to store a copy of your source code, queries, and files. The concept here is similar to that of GitHub or Azure DevOps. The difference is your code remains within the context of your workspace. To create a local Git Repo, select the Repos menu option and click the Add Repo button. A window prompts you to either clone an existing remote Git repository or create a local empty one and clone a remote one later. You will see something similar to that shown in Figure 3.73.
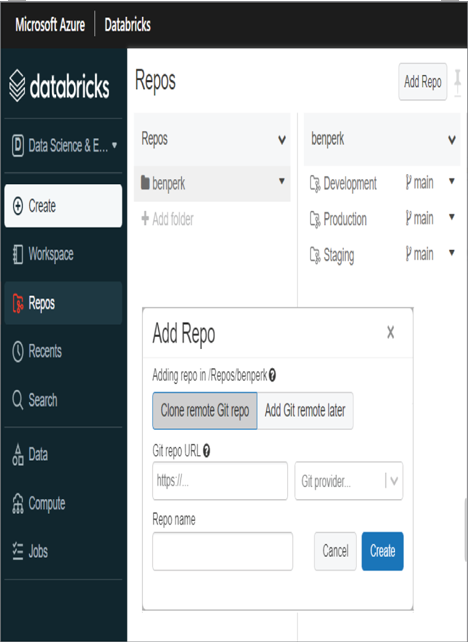
FIGUER 3.73 Azure Databricks Repos
Notice that Figure 3.73 shows three Repos, one for each stage of the release process. This is only an example of the numerous approaches for building a configuration and release management process. Remember that this kind of source code management process requires thought, a design, management, security, and control.
Data
The Data section provides features for creating, managing, and viewing the structure of the data stored in the workspace. When you click the Data section, a pop‐out menu will render that contains a navigation hierarchy between catalogs, databases, and tables.
Catalogs
A catalog is the top‐level logical container and consists of metadata definitions of the databases and tables contained within it. Catalogs enable you to organize and structure your data into more logical groupings. You gain the same benefits from this kind of organization as you realize with Management Groups ➢ Subscriptions ➢ Resource Groups in Azure. For example, if you happen to be working on projects from different companies but are using the same workspace, you might consider separating the data at the highest possible logical level.
Databases
When you click an existing catalog (for example, hive_metastore), the list of databases consisting within it are rendered. Multiple databases can exist in a catalog, as shown previously in Figure 3.21. This is another level of separation that is helpful for managing the logical organization of data. Consider an example where you work on the analysis of brain waves that use an assortment of different devices. An option for organizing the data could be to place different device‐bound brain waves into different databases.
Tables
The final grouping in the pop‐out menu contains a list of all the tables within the selected database. When you select the table, it will render the details (aka metadata) for the table, similar to Figure 3.23.
Compute
The capabilities found in the Compute section provide the means for creating, listing, and configuring all‐purpose clusters, job clusters, pools, and cluster policies.